Виктор Кустов. Informix. Руководство администратора баз данных
---------------------------------------------------------------
Email: visor@olma.co.ru
---------------------------------------------------------------
1. Теоретические основы. *
1.1 Понятие СУБД сервера. *
1.1.1 Основные функции СУБД *
1.1.2 Типовая организация современной СУБД *
1.2 Понятие архитектуры клиент-сервер. *
2. Теоретические основы СУБД сервера Informix OnLine v.7.X *
2.1 СУБД сервер Informix. *
2.2 Архитектура СУБД сервера Informix OnLine v.7.X *
2.2.1 . Динамическая масштабируемая архитектура *
2.2.1.1 Потоки *
2.2.1.2 Виртуальные процессоры *
2.2.1.3 Планирование потоков *
2.2.1.4 Разделение потоков между виртуальными процессорами. *
2.2.1.5 Экономия памяти и других ресурсов *
2.2.2 Организация разделяемой памяти *
2.2.3 Организация операций обмена с дисками *
2.2.3.1 Управление дисковой памятью *
2.2.3.2 Асинхронный ввод-вывод *
2.2.3.3 Опережающее чтение *
2.2.4 Поддержка фрагментации таблиц и индексов *
2.2.5 Параллельная обработка запросов *
2.2.5.1 На чем основана технология PDQ *
2.2.5.2 Итераторы *
2.2.5.3 Примеры применения параллелизма *
2.2.5.4 Баланс между OLTP и DSS-приложениями *
2.2.6 Оптимизатор выполнения запросов по стоимости *
2.2.7 Средства обеспечения надежности *
2.2.7.1 . Зеркалирование дисковых областей *
2.2.7.2 Тиражирование *
2.2.7.3 Быстрое восстановление при включении системы *
2.2.7.4 Архивирование и восстановление данных *
2.2.8 Динамическое администрирование *
2.2.8.1 Интерфейс мониторинга системы *
2.2.8.2 Утилита DB/Cockpit *
2.2.8.3 Утилита OnPerf *
2.2.8.4 Утилита параллельной загрузки *
2.2.9 Распределенные вычисления *
2.2.9.1 Взаимодействие клиент-сервер *
2.2.9.2 Прозрачность расположения данных *
2.2.9.3 Распределенные базы данных и протокол двухфазовой фиксации транзакций *
2.2.10 Поддержка национальных языков *
2.2.11 Средства безопасности класса С2 *
2.3 Дополнительные компоненты компании Informix для выполнения специфических задач. *
2.3.1 Informix-Enterprise Gateway 7.1 *
2.3.2 Технология и компоненты EDA/SQL *
2.3.2.1 EDA API/SQL *
2.3.2.2 EDA/Link *
2.3.2.3 EDA/SQL Server *
2.3.2.4 EDA/Data Drivers *
2.3.3 Возможности Enterprise Gateway *
2.3.3.1 Прозрачный доступ для чтения и записи *
2.3.3.2 Распределенные соединения *
2.3.3.3 Конфигурирование Enterprise Gateway *
2.3.3.4 Безопасность *
2.3.4 Библиотеки сопряжения сервера Informix-OnLine DS с менеджерами транзакций: Informix-TP/XA и Informix-TP/TOOLKIT *
2.4 Заключение *
2.5 Литература *
1. Теоретические основы.
1.1 Понятие СУБД сервера.
Традиционных возможностей файловых систем оказывается недостаточно для построения даже простых информационных систем. При построении информационной системы требуется обеспечить: поддержание логически согласованного набора данных; обеспечение языка манипулирования данными; восстановление информации после разного рода сбоев; реально параллельная работа нескольких пользователей. Для выполнения всех этих задачь выделяется группа программ, обьедененных в единый программный комплекс. Этот комплекс носит название система управления базами данных (СУБД). Сформулируем эти (и другие) важные функции отдельно.
1.1.1 Основные функции СУБД
К числу функций СУБД принято относить следующее:
1. Непосредственное управление данными во внешней памяти
Эта функция включает обеспечение необходимых структур внешней памяти как для хранения непосредственных данных, входящих в БД, так и для служебных целей, например, для убыстрения доступа к данным в некоторых случаях (обычно для этого используются индексы). В некоторых реализациях СУБД активно используются возможности существующих файловых систем, в других работа производится вплоть до уровня устройств внешней памяти. Но подчеркнем, что в развитых СУБД пользователи в любом случае не обязаны знать, использует ли СУБД файловую систему, а если использует, то как организованы файлы. В частности, СУБД поддерживает собственную систему именования объектов БД (это очень важно, поскольку имена объектов базы данных соответствуют именам объектов предметной области).
Существует множество различных способов организации внешней памяти баз данных. Как и все решения, принимаемые при организации баз данных, конкретные методы организации внешней памяти необходимо выбирать в тесной связи со всеми остальными решениями.
2. Управление буферами оперативной памяти
СУБД обычно работают с БД значительного размера; по крайней мере этот размер обычно существенно превышает доступный объем оперативной памяти. Понятно, если при обращении к любому элементу данных будет производиться обмен с внешней памятью, то вся система будет работать со скоростью устройства внешней памяти. Единственным же способом реального увеличения этой скорости является буферизация данных в оперативной памяти. И даже если операционная система производит общесистемную буферизацию (как в случае ОС UNIX), этого недостаточно для целей СУБД, которая располагает гораздо большей информацией о полезности буферизации той или иной части БД. Поэтому в развитых СУБД поддерживается собственный набор буферов оперативной памяти с собственной дисциплиной замены буферов. При управлении буферами основной памяти приходится разрабатывать и применять согласованные алгоритмы буферизации, журнализации и синхронизации. Заметим, что существует отдельное направление СУБД, которые ориентированы на постоянное присутствие в оперативной памяти всей БД. Это направление основывается на предположении, что в предвидимом будущем объем оперативной памяти компьютеров сможет быть настолько велик, что позволит не беспокоиться о буферизации. Пока эти работы находятся в стадии исследований.
3. Управление транзакциями
Транзакция - это последовательность операций над БД, рассматриваемых СУБД как единое целое. Либо транзакция успешно выполняется, и СУБД фиксирует (COMMIT) изменения БД, произведенные ею, во внешней памяти, либо ни одно из этих изменений никак не отражается в состоянии БД. Понятие транзакции необходимо для поддержания логической целостности БД. Если вспомнить наш пример информационной системы отдела кадров с файлами СОТРУДНИКИ и ОТДЕЛЫ, то единственным способом не нарушить целостность БД при выполнении операции приема на работу нового сотрудника будет объединение элементарных операций над файлами СОТРУДНИКИ и ОТДЕЛЫ в одну транзакцию. Таким образом, поддержание механизма транзакций - обязательное условие даже однопользовательских СУБД (если, конечно, такая система заслуживает названия СУБД). Но понятие транзакции гораздо существеннее во многопользовательских СУБД. То свойство, что каждая транзакция начинается при целостном состоянии БД и оставляет это состояние целостным после своего завершения, делает очень удобным использование понятия транзакции как единицы активности пользователя по отношению к БД. При соответствующем управлении параллельно выполняющимися транзакциями со стороны СУБД каждый пользователь может в принципе ощущать себя единственным пользователем СУБД (на самом деле, это несколько идеализированное представление, поскольку пользователи многопользовательских СУБД порой могут ощутить присутствие своих коллег).
С управлением транзакциями в многопользовательской СУБД связаны важные понятия сериализации транзакций и сериального плана выполнения смеси транзакций. Под сериализаций параллельно выполняющихся транзакций понимается такой порядок планирования их работы, при котором суммарный эффект смеси транзакций эквивлентен эффекту их некоторого последовательного выполнения. Сериальный план выполнения смеси транзакций - это такой способ их совместного выполнения, который приводит к сериализации транзакций. Понятно, что если удается добиться действительно сериального выполнения смеси транзакций, то для каждого пользователя, по инициативе которого образована транзакция, присутствие других транзакций будет незаметно (если не считать некоторого замедления работы для каждого пользователя по сравнению с однопользовательским режимом).
Существует несколько базовых алгоритмов сериализации транзакций. В централизованных СУБД наиболее распространены алгоритмы, основанные на синхронизационных захватах объектов БД. При использовании любого алгоритма сериализации возможны ситуации конфликтов между двумя или более транзакциями по доступу к объектам БД. В этом случае для поддержания сериализации необходимо выполнить откат (ликвидировать все изменения, произведенные в БД) одной или более транзакций. Это один из случаев, когда пользователь многопользовательской СУБД может реально (и достаточно неприятно) ощутить присутствие в системе транзакций других пользователей.
4. Журнализация
Одно из основных требований к СУБД - надежное хранение данных во внешней памяти. Под надежностью хранения понимается то, что СУБД должна быть в состоянии восстановить последнее согласованное состояние БД после любого аппаратного или программного сбоя. Обычно рассматриваются два возможных вида аппаратных сбоев: так называемые мягкие сбои, которые можно трактовать как внезапную остановку работы компьютера (например, аварийное выключение питания), ижесткие сбои, характеризуемые потерей информации на носителях внешней памяти. Примерами программных сбоев могут быть аварийное завершение работы СУБД (из-за ошибки в программе или некоторого аппаратного сбоя) или аварийное завершение пользовательской программы, в результате чего некоторая транзакция остается незавершенной. Первую ситуацию можно рассматривать как особый вид мягкого аппаратного сбоя; при возникновении последней требуется ликвидировать последствия только одной транзакции.
Но в любом случае для восстановления БД нужно располагать некоторой дополнительной информацией. Другими словами, поддержание надежного хранения данных в БД требует избыточности хранения данных, причем та их часть, которая используется для восстановления, должна храниться особо надежно. Наиболее распространенный метод поддержания такой избыточной информации - ведение журнала изменений БД.
Журнал - это особая часть БД, недоступная пользователям СУБД и поддерживаемая особо тщательно (иногда поддерживаются две копии журнала, располагаемые на разных физических дисках), в которую поступают записи обо всех изменениях основной части БД. В разных СУБД изменения БД журнализуются на разных уровнях: иногда запись в журнале соответствует некоторой логической операции изменения БД (например, операции удаления строки из таблицы реляционной БД), а порой запись соответствует минимальной внутренней операции модификации страницы внешней памяти. В некоторых системах одновременно используются оба подхода.
Во всех случаях придерживаются стратегии "упреждающей" записи в журнал (так называемого протокола Write Ahead Log - WAL). Грубо говоря, эта стратегия заключается в том, что запись об изменении любого объекта БД должна попасть во внешнюю память журнала раньше, чем измененный объект попадет во внешнюю память основной части БД. Известно, если в СУБД корректно соблюдается протокол WAL, то с помощью журнала можно решить все проблемы восстановления БД после любого сбоя.
Самая простая ситуация восстановления - индивидуальный откат транзакции. Строго говоря, для этого не требуется общесистемный журнал изменений БД. Достаточно для каждой транзакции поддерживать локальный журнал операций модификации БД, выполненных в этой транзакции, и производить откат транзакции выполнением обратных операций, следуя от конца локального журнала. В некоторых СУБД так и делают, но в большинстве систем локальные журналы не поддерживают, а индивидуальный откат транзакции выполняют по общесистемному журналу, для чего все записи от одной транзакции связывают обратным списком (от конца к началу).
При мягком сбое во внешней памяти основной части БД могут находиться объекты, модифицированные транзакциями, не закончившимися к моменту сбоя, и могут отсутствовать объекты, модифицированные транзакциями, которые к моменту сбоя успешно завершились (по причине использования буферов оперативной памяти, содержимое которых при мягком сбое пропадает). При соблюдении протокола WAL во внешней памяти журнала должны гарантированно находиться записи, относящиеся к операциям модификации обоих видов объектов. Целью процесса восстановления после мягкого сбоя является состояние внешней памяти основной части БД, которое возникло бы при фиксации во внешней памяти изменений всех завершившихся транзакций и которое не содержало бы никаких следов незаконченных транзакций. Чтобы этого добиться, сначала производят откат незавершенных транзакций (undo), а потом повторно воспроизводят (redo) те операции завершенных транзакций, результаты которых не отображены во внешней памяти. Этот процесс содержит много тонкостей, связанных с общей организацией управления буферами и журналом. Более подробно мы рассмотрим это в соответствующей лекции.
Для восстановления БД после жесткого сбоя используют журнал и архивную копию БД. Грубо говоря, архивная копия - это полная копия БД к моменту начала заполнения журнала (имеется много вариантов более гибкой трактовки смысла архивной копии). Конечно, для нормального восстановления БД после жесткого сбоя необходимо, чтобы журнал не пропал. Как уже отмечалось, к сохранности журнала во внешней памяти в СУБД предъявляются особо повышенные требования. Тогда восстановление БД состоит в том, что исходя из архивной копии по журналу воспроизводится работа всех транзакций, которые закончились к моменту сбоя. В принципе можно даже воспроизвести работу незавершенных транзакций и продолжить их работу после конца восстановления. Однако в реальных системах это обычно не делается, поскольку процесс восстановления после жесткого сбоя является достаточно длительным.
5. Языки БД
Для работы с базами данных используются специальные языки, в целом называемые языками баз данных. В ранних СУБД поддерживалось несколько специализированных по своим функциям языков. Чаще всего выделялись два - язык определения схемы БД (SDL - Schema Definition Language) и язык манипулирования данными (DML - Data Manipulation Language). SDL служил главным образом для определения логической структуры БД, т.е. той структуры БД, какой она представляется пользователям. DML содержал набор операторов манипулирования данными, т.е. операторов, позволяющих заносить данные в БД, удалять, модифицировать или выбирать существующие данные. Мы рассмотрим более подробно языки ранних СУБД в следующей лекции.
В современных СУБД обычно поддерживается единый интегрированный язык, содержащий все необходимые средства для работы с БД, начиная от ее создания и обеспечивающий базовый пользовательский интерфейс с базами данных. Стандартным языком наиболее распространенных в настоящее время реляционных СУБД является язык SQL (Structured Query Language). В нескольких лекциях этого курса язык SQL будет рассматриваться достаточно подробно, а пока мы перечислим основные функции реляционной СУБД, поддерживаемые на "языковом" уровне (т.е. функции, поддерживаемые при реализации интерфейса SQL).
Прежде всего язык SQL сочетает средства SDL и DML, т.е. позволяет определять схему реляционной БД и манипулировать данными. При этом именование объектов БД (для реляционной БД - именование таблиц и их столбцов) поддерживается на языковом уровне в том смысле, что компилятор языка SQL производит преобразование имен объектов в их внутренние идентификаторы на основании специально поддерживаемых служебных таблиц-каталогов. Внутренняя часть СУБД (ядро) вообще не работает с именами таблиц и их столбцов.
Язык SQL содержит специальные средства определения ограничений целостности БД. Опять же ограничения целостности хранятся в специальных таблицах-каталогах, и обеспечение контроля целостности БД производится на языковом уровне, т.е. при компиляции операторов модификации БД компилятор SQL на основании имеющихся в БД ограничений целостности генерирует соответствующий программный код.
Специальные операторы языка SQL позволяют определять так называемые представления БД, фактически являющиеся хранимыми в БД запросами (результатом любого запроса к реляционной БД является таблица) с именованными столбцами. Для пользователя представление является такой же таблицей, как любая базовая таблица, хранимая в БД, но с помощью представлений можно ограничить или наоборот расширить видимость БД для конкретного пользователя. Поддержание представлений производится также на языковом уровне.
Наконец, авторизация доступа к объектам БД производится на основе специального набора операторов SQL. Идея состоит в том, что для выполнения операторов SQL разного вида пользователь должен обладать различными полномочиями. Пользователь, создавший таблицу БД, обладает полным набором полномочий для работы с этой таблицей. В их число входит полномочие на передачу всех или части полномочий другим пользователям, включая полномочие на передачу полномочий. Полномочия пользователей описываются в специальных таблицах-каталогах, контроль полномочий поддерживается на языковом уровне.
1.1.2 Типовая организация современной СУБД
Естественно, организация типичной СУБД и состав ее компонентов соответствует рассмотренному нами набору функций.
Логически в современной реляционной СУБД можно выделить наиболее внутреннюю часть - ядро СУБД (часто его называют Data Base Engine), компилятор языка БД (обычно SQL), подсистему поддержки времени выполнения, набор утилит. В некоторых системах эти части выделяются явно, в других - нет, но логически такое разделение можно провести во всех СУБД.
Ядро СУБД отвечает за управление данными во внешней памяти, управление буферами оперативной памяти, управление транзакциями и журнализацию. Соответственно можно выделить такие компоненты ядра (по крайней мере, логически, хотя в некоторых системах эти компоненты выделяются явно), как менеджер данных, менеджер буферов, менеджер транзакций и менеджер журнала. Как можно было понять из первой части этой лекции, функции этих комонентов взаимосвязаны, и для обеспечения корректной работы СУБД все эти компоненты должны взаимодействовать по тщательно продуманным и проверенным протоколам. Ядро СУБД обладает собственным интерфейсом, не доступным пользователям напрямую и используемым в программах, производимых компилятором SQL (или в подсистеме поддержки выполнения таких программ), и утилитах БД. Ядро СУБД является основной резидентной частью СУБД. При использовании архитектуры "клиент-сервер" ядро является основным составляющим серверной части системы.
Основная функция компилятора языка БД - компиляция операторов языка БД в некоторую выполняемую программу.
Основной проблемой реляционных СУБД является то, что языки этих систем (а это, как правило, SQL) являются непроцедурными, т.е. в операторе такого языка специфицируется некоторое действие над БД, но эта спецификация не процедура, она лишь описывает в некоторой форме условия совершения желаемого действия (вспомните примеры из первой лекции). Поэтому компилятор должен решить, каким образом выполнять оператор языка, прежде чем произвести программу. Применяются достаточно сложные методы оптимизации операторов, которые мы подробно рассмотрим в следующих лекциях. Результатом компиляции является выполняемая программа, представляемая в некоторых системах в машинных кодах, но более часто в выполняемом внутреннем машинно-независимом коде. В последнем случае реальное выполнение оператора производится с привлечением подсистемы поддержки времени выполнения, представляющей собой, по сути дела, интерпретатор этого внутреннего языка.
Наконец, в отдельные утилиты БД обычно выделяют такие процедуры, которые слишком накладно выполнять с использованием языка БД, например, загрузка и разгрузка БД, сбор статистики, глобальная проверка целостности БД и т.д. Утилиты программируются с использованием интерфейса ядра СУБД, а иногда даже с проникновением внутрь ядра.
1.2 Понятие архитектуры клиент-сервер.
В подавляющем большинстве случаев локальная сеть используется для коллективного доступа к базам данных.
Существует два подхода к организации коллективного доступа данным. Первый подход заключается в том , что файлы данных располагают на дисках файл сервера и все рабочие станции получают к нему доступ. Этот подход носит название архитектура "файл-сервер". Если файлы данных расположены на сервере ( в данном случае сервер называется "файл-сервер" ) , с ними одновременно работают несколько программ , запущенных на рабочих станциях. При этом программы должны сами следить за тем , чтобы изменяемые записи базы данных блокировались для записи и чтения со стороны других программ во время изменений. Данный метод имеет существенный недостаток: файл-сервер не обеспечивает достаточную производительность при большом количестве рабочих станций.
Второй подход носит название архитектура "клиент-сервер".
Определения:
Клиент - Рабочая станция для одного пользователя, обеспечивающая режим регистрации и др. необходимые на его рабочем месте функции вычисления, коммуникацию, доступ к базам данных и др.
Сервер - один или несколько многопользовательских процессоров с единым полем памяти, который в соответствии с потребностями пользователя обеспечивает им функции вычисления, коммуникации и доступа к базам данных.
Обработка Клиент - Сервер - среда, в которой обработка приложений распределена между клиентом и сервером. Нередко в обработке участвуют машины разных типов, причем клиент и сервер общаются между собой с помощью фиксированного множества стандартных протоколов обмена и процедур обращения к удаленным платформам.
СУБД с персональных ЭВМ ( такие, как Clipper, DBase, FoxPro, Paradox, Clarion имеют сетевые версии, которые просто совместно используют файлы баз данных тех же форматов для ПК, осуществляя при этом сетевые блокировки для разграничения доступа к таблицам и записям. При этом вся работа осуществляется на ПК. Сервер используется просто как общий удаленный диск большой емкости. Такой способ работы приводит к риску потери данных при аппаратных сбоях.
По сравнению с такими системами системы , построенные в архитектуре Клиент - Сервер, имеют следующие преимущества:
- позволяют увеличить размер и сложность программ, выполняемых на рабочей станции;
- обеспечивает перенесение наиболее трудоемких опе-раций на сервер, являющийся машиной большей вычислительной мощности;
- уменьшает до минимума возможность потери содержащейся в БД информации за счет применения имеющихся на сервере внутренних механизмов защиты данных , таких , как , например системы трассировки транзакций, откат после сбоя, средства обеспечения целостности данных;
- в несколько раз уменьшает объем информации, передаваемый по сети.
2. Теоретические основы СУБД сервера Informix OnLine v.7.X
2.1 СУБД сервер Informix.
Работы над системой управления базами данных Informix были начаты в 1980 г. Согласно начальному замыслу программный комплекс Informix рассматривался как СУБД, специально ориентированная для работы в среде ОС UNIX. Для организации хранения данных был выбран реляционный подход. С тех пор Informix стал одной из основных СУБД, работающих в среде UNIX.
Сейчас продукты Informix уже установлены практически на всех UNIX-компьютерах. Среди всех ОЕМ фирма выбрала шесть стратегических партнеров. Это: Sequent, HP, SUN, IBM, Siemens Nixdorf, NCR. Портирование продуктов фирмы на производимые стратегическими партнерами платформы производится в первую очередь. Практически это означает, что при появлении на рынке новой платформы или новой версии операционной системы для платформы уже имеется соответствующая версия продуктов Informix.
Среди не UNIX платформ Informix поддерживает NetWare, Windows, Windows NT и DOS.
Фирма Informix объявила и поддерживает программу InSync. Программа объединяет независимых разработчиков программного обеспечения. В рамках этой программы созданы программные интерфейсы для связи с СУБД других производителей, в частности СУБД, функционирующие на не UNIX-платформах.
2.1.1 Описание продуктов Informix
Продукты Informix содержат серверы баз данных, средства разработки и отладки, коммуникационные средства. Характерной особенностью Informix является наличие нескольких типов серверов, подробнее о них будет сказано ниже.
Начиная с версии 4.0 фирма Informix поставляет сервер базы данных OnLine, который поддерживает аппарат распределенных транзакций (технология OLTP - on-line transaction processing), что позволяет по-новому подходить к созданию баз данных с очень большим объемом хранимой информации.
Кроме того, в Informix-OnLine включен новый тип данных - битовые поля (BLOB - binary large objects). Битовые поля могут использоваться для мультимедийных приложений (хранение изображений и звука).
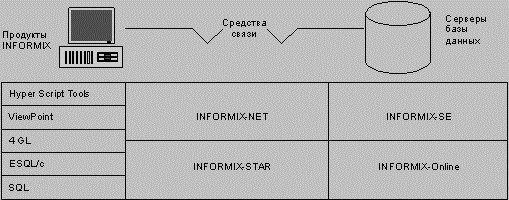 2.1.2 Типовые конфигурации
В основе систем, разработанных на основе СУБД Informix, лежит принцип архитектуры "клиент-сервер". Клиент - это пользовательская прикладная программа, обеспечивающая взаимодействие (интерфейс) базы данных с пользователем. Всю работу, связанную с доступом и модификацией базы данных, выполняет сервер базы данных (БД-сервер).
Сервер базы данных (database engine), он же ядро базы данных - это отдельная программа, выполняемая как отдельный процесс. Сервер передает выбранную из базы информацию по каналу клиенту. Именно сервер работает с данными, заботится об их размещении на диске. Технологию "клиент-сервер" со стороны сервера обеспечивают модули Informix-SE, Informix-Online или Informix OnLine-Dynamic Server.
Informix-SE представляет собой сервер базы данных, предназначенный для обеспечения работы в системах с малым или средним объемом информации.
2.1.2 Типовые конфигурации
В основе систем, разработанных на основе СУБД Informix, лежит принцип архитектуры "клиент-сервер". Клиент - это пользовательская прикладная программа, обеспечивающая взаимодействие (интерфейс) базы данных с пользователем. Всю работу, связанную с доступом и модификацией базы данных, выполняет сервер базы данных (БД-сервер).
Сервер базы данных (database engine), он же ядро базы данных - это отдельная программа, выполняемая как отдельный процесс. Сервер передает выбранную из базы информацию по каналу клиенту. Именно сервер работает с данными, заботится об их размещении на диске. Технологию "клиент-сервер" со стороны сервера обеспечивают модули Informix-SE, Informix-Online или Informix OnLine-Dynamic Server.
Informix-SE представляет собой сервер базы данных, предназначенный для обеспечения работы в системах с малым или средним объемом информации.
 Хранение данных в этом случае осуществляется в файловой системе операционной системы, что значительно упрощает разработку и эксплуатацию приложений.
Клиенты и серверы могут находиться на одном компьютере, либо на нескольких, связанных между собой сетью. Подобное разделение функций дает высокую производительность и максимальную гибкость. Для обеспечения отношений связи типа "клиент-сервер" между различными компьютерами со стороны сервера применяется модуль Informix-NET.
Informix-OnLine - это сервер второго поколения, обеспечивающий технологию распределенных транзакций (OLTP - on-line transaction processing). Технология распределенных транзакций позволяет выполнять запросы в распределенной базе данных, физически находящихся на различных компьютерах. По сравнению с Informix-SE сервер Informix-OnLine имеет специальный тип данных - битовые поля (BLOB - Binary Large Objects), символьные строки переменной длины, буферизацию транзакций, зеркальный диск, автоматическое восстановление после системных сбоев, большую скорость (в 2-4 раза).
Модуль Informix-Star является средством поддержки работы с распределенными базами данных. Посредством модуля InformixStar осуществляется оперативная обработка транзакций.
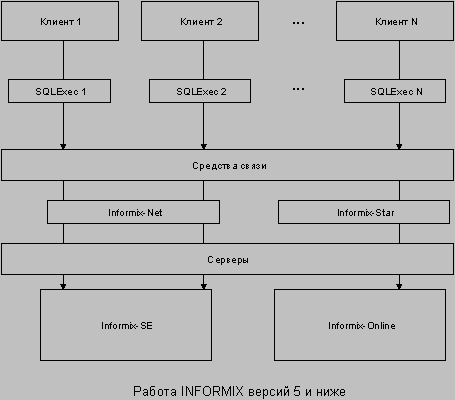
Работа сервера Informix заключается в запуске специальной программы (SQLEXEC для Informix-SE и SQLTURBO для Informix-OnLine), которая обеспечивает работу всех SQL-операторов. Для каждого клиента запускается процесс операционной системы, использующий эту программу. В случае, если клиент прервал работу, но не вышел из своей задачи, то его процесс занимает ресурсы системы, снижая ее производительность.
Хранение данных в этом случае осуществляется в файловой системе операционной системы, что значительно упрощает разработку и эксплуатацию приложений.
Клиенты и серверы могут находиться на одном компьютере, либо на нескольких, связанных между собой сетью. Подобное разделение функций дает высокую производительность и максимальную гибкость. Для обеспечения отношений связи типа "клиент-сервер" между различными компьютерами со стороны сервера применяется модуль Informix-NET.
Informix-OnLine - это сервер второго поколения, обеспечивающий технологию распределенных транзакций (OLTP - on-line transaction processing). Технология распределенных транзакций позволяет выполнять запросы в распределенной базе данных, физически находящихся на различных компьютерах. По сравнению с Informix-SE сервер Informix-OnLine имеет специальный тип данных - битовые поля (BLOB - Binary Large Objects), символьные строки переменной длины, буферизацию транзакций, зеркальный диск, автоматическое восстановление после системных сбоев, большую скорость (в 2-4 раза).
Модуль Informix-Star является средством поддержки работы с распределенными базами данных. Посредством модуля InformixStar осуществляется оперативная обработка транзакций.
Работа сервера Informix заключается в запуске специальной программы (SQLEXEC для Informix-SE и SQLTURBO для Informix-OnLine), которая обеспечивает работу всех SQL-операторов. Для каждого клиента запускается процесс операционной системы, использующий эту программу. В случае, если клиент прервал работу, но не вышел из своей задачи, то его процесс занимает ресурсы системы, снижая ее производительность.
 Одним из последних достижений фирмы стал выпуск нового сервера базы данных OnLine Dynamic Server, которой входит в состав системы начиная с версии 6.0. Этот продукт основан на так называемой Динамической Масштабируемой Архитектуре (Dynamically Scalable Architecture - DSA), которая специально ориентирована на работу с многопроцессорными системами. OnLine Dynamic Server обеспечивает повышение производительности за счет гибкости использования ресурсов СУБД, использование многопоточной архитектуры. Фактически OnLine Dynamic Server берет на себя многие связанные с распределением ресурсов функции операционной системы. В результате уменьшается нагрузка на операционную системы, что в конечном счете приводит к росту производительности.
Одним из последних достижений фирмы стал выпуск нового сервера базы данных OnLine Dynamic Server, которой входит в состав системы начиная с версии 6.0. Этот продукт основан на так называемой Динамической Масштабируемой Архитектуре (Dynamically Scalable Architecture - DSA), которая специально ориентирована на работу с многопроцессорными системами. OnLine Dynamic Server обеспечивает повышение производительности за счет гибкости использования ресурсов СУБД, использование многопоточной архитектуры. Фактически OnLine Dynamic Server берет на себя многие связанные с распределением ресурсов функции операционной системы. В результате уменьшается нагрузка на операционную системы, что в конечном счете приводит к росту производительности.
 Для обслуживания клиентов запускаются "виртуальные процессоры" - процессы операционной системы, которые устанавливают связь между клиентом и ядром Informix. Связь устанавливается с помощью специальных "нитей" (thread), которые активизируются только если клиент активен и обращается к серверу базы данных. В случае, если клиент неактивен, "нить" может обслуживать других клиентов.
Число виртуальных процессоров определяет администратор базы данных, исходя из реальных ресурсов вычислительной системы и сети клиентов. Если вычислительная система является многопроцессорной, то разные виртуальные процессоры могут обслуживаться разными реальными процессорами.
В версии 6.0 сетевые функции заложены в ядре СУБД. Поэтому для функционирования в сети OnLine Dynamic Server модули Informix-Net или Informix-Star не требуются.
2.2 Архитектура СУБД сервера Informix OnLine v.7.X
К СУБД, претендующим на роль информационной основы современных предприятий, предъявляются все новые и более жесткие требования. К числу важнейших можно отнести следующие:
Для обслуживания клиентов запускаются "виртуальные процессоры" - процессы операционной системы, которые устанавливают связь между клиентом и ядром Informix. Связь устанавливается с помощью специальных "нитей" (thread), которые активизируются только если клиент активен и обращается к серверу базы данных. В случае, если клиент неактивен, "нить" может обслуживать других клиентов.
Число виртуальных процессоров определяет администратор базы данных, исходя из реальных ресурсов вычислительной системы и сети клиентов. Если вычислительная система является многопроцессорной, то разные виртуальные процессоры могут обслуживаться разными реальными процессорами.
В версии 6.0 сетевые функции заложены в ядре СУБД. Поэтому для функционирования в сети OnLine Dynamic Server модули Informix-Net или Informix-Star не требуются.
2.2 Архитектура СУБД сервера Informix OnLine v.7.X
К СУБД, претендующим на роль информационной основы современных предприятий, предъявляются все новые и более жесткие требования. К числу важнейших можно отнести следующие:
- высокая производительность
- масштабируемость
- смешанная загрузка сервера разными типами задач
- непрерывная доступность данных
Данный раздел посвящен, главным образом, рассмотрению архитектурных особенностей и механизмов сервера INFORMIX-OnLine DS, направленных на удовлетворение перечисленных выше требований. Приводится также информация о средствах распределенных вычислений, безопасности, поддержки национальной среды.
2.2.1 . Динамическая масштабируемая архитектура
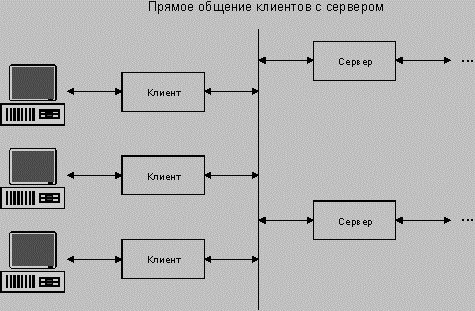
Архитектура сервера INFORMIX-OnLine DS получила название "динамическая масштабируемая архитектура" (DSA). Суть ее заключается в том, что одновременно выполняется относительно небольшое число серверных процессов (виртуальных процессоров), которые разделяют между собой работу по обслуживанию множества клиентов. По сравнению с более ранними моделями сервера INFORMIX, где для каждого клиента создавался индивидуальный серверный процесс (рис. 1), новая модель обладает рядом преимуществ:
- снижение нагрузки на операционную систему (число серверных процессов невелико);
- сокращение совокупной потребности клиентов в оперативной памяти;
- снижение конкуренции при одновременном использовании системных ресурсов;
- более рациональное по сравнению с ОС назначение приоритетов и планирование;
Для многопроцессорных платформ:
>
- равномерная загрузка наличных процессоров;
- ускорение обработки сложных запросов за счет параллельного выполнения на нескольких процессорах.
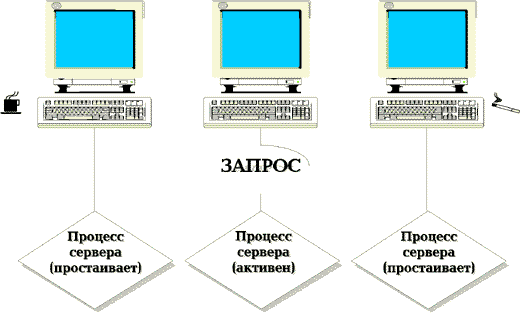 Рис. 1. Модель "один клиент - один серверный процесс".
Пока пользователь анализирует результаты или готовит очередной запрос, серверный процесс простаивает, занимая системные ресурсы.
Архитектура DSA полностью использует возможности симметричных многопроцессорных платформ SMP (Symmetric Multiprocessing systems), и может работать на однопроцессорных платформах. В последующих версиях предполагается расширить архитектуру сервера, обеспечив поддержку слабосвязанных систем и систем с массовым параллелизмом (MPP). Все базовые технологии DSA являются встроенными, они включены в библиотеки сервера, и их применение не зависит от особенностей ОС или аппаратных платформ различных поставщиков.
2.2.1.1 Потоки
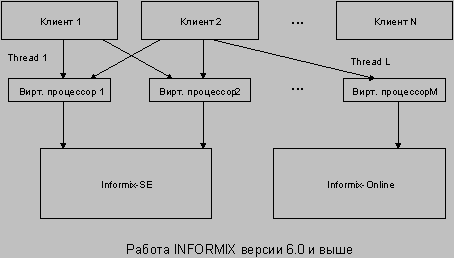
Архитектуру INFORMIX-OnLine DS называют также многопотоковой. Для каждого клиента создается так называемый поток, или нить (thread). Поток - это подзадача, выполняемая в рамках одного из серверных процессов.
В некоторых случаях для обслуживания одного клиентского запроса создается несколько параллельных потоков. Потоки создаются также для выполнения внутренних задач сервера - ввода-вывода, журнализации, администрирования и др. Таким образом, одновременно выполняется множество потоков, которые распределяются между наличными виртуальными процессорами (рис. 2).
Рис. 1. Модель "один клиент - один серверный процесс".
Пока пользователь анализирует результаты или готовит очередной запрос, серверный процесс простаивает, занимая системные ресурсы.
Архитектура DSA полностью использует возможности симметричных многопроцессорных платформ SMP (Symmetric Multiprocessing systems), и может работать на однопроцессорных платформах. В последующих версиях предполагается расширить архитектуру сервера, обеспечив поддержку слабосвязанных систем и систем с массовым параллелизмом (MPP). Все базовые технологии DSA являются встроенными, они включены в библиотеки сервера, и их применение не зависит от особенностей ОС или аппаратных платформ различных поставщиков.
2.2.1.1 Потоки
Архитектуру INFORMIX-OnLine DS называют также многопотоковой. Для каждого клиента создается так называемый поток, или нить (thread). Поток - это подзадача, выполняемая в рамках одного из серверных процессов.
В некоторых случаях для обслуживания одного клиентского запроса создается несколько параллельных потоков. Потоки создаются также для выполнения внутренних задач сервера - ввода-вывода, журнализации, администрирования и др. Таким образом, одновременно выполняется множество потоков, которые распределяются между наличными виртуальными процессорами (рис. 2).
 Рис.2. Многопотоковая модель. Виртуальные процессоры (ВП) не простаивают, если имеются готовые к выполнению пользовательские или системные потоки.
INFORMIX-OnLine DS не полагается на механизмы потоков, имеющиеся в некоторых операционных системах. Он формирует потоки, специфичные для задач обработки баз данных, оптимальные в отношении выделяемой под них памяти, методов планирования и числа инструкций, затрачиваемых на переключение между потоками.
2.2.1.2 Виртуальные процессоры
Виртуальным процессором называется процесс сервера баз данных. Виртуальный процессор можно сравнить с операционной системой. Поток по отношению к нему выступает как процесс, подобно тому, как сам виртуальный процессор является процессом с точки зрения операционной системы.
Виртуальные процессоры (ВП) являются специализированными - они подразделяются на классы в соответствии с типом потоков, для выполнения которых они предназначены. Примеры классов ВП:
CPU - Потоки обслуживания клиентов, реализуют оптимизацию и логику выполнения запросов. К этому классу относятся и некоторые системные потоки.
AIO - Операции асинхронного обмена с диском.
ADM - Административные функции, например, системный таймер.
TLI - Контроль сетевого взаимодействия посредством интерфейса TLI (Transport Layer Interface).
В отличие от операционной системы, которая должна обеспечивать выполнение произвольных процессов, классы виртуальных процессоров спроектированы для наиболее оптимального выполнения заданий определенного вида.
Начальное число виртуальных процессоров каждого класса, создаваемых при запуске INFORMIX-OnLine DS, задается в конфигурационном файле. Однако, потребности в каждом виде обработки не всегда предсказуемы. Инструменты администрирования позволяют динамически, не останавливая сервер, запустить дополнительные виртуальные процессоры. Например, если растет очередь потоков к виртуальным CPU-процессорам, то можно увеличить их число. Точно так же, возможно добавление виртуальных процессоров обмена с дисками, сетевых процессоров взаимодействия с клиентами, создание процессора обмена с оптическим диском, если он отсутствовал в начальной конфигурации. Динамически сократить можно только число виртуальных процессоров класса CPU.
На некоторых мультипроцессорных платформах, где OnLine DS поддерживает родство процессоров (processor affinity), допускается привязка виртуальных CPU-процессоров к определенным центральным процессорам компьютера. В результате производительность виртуального CPU-процессора повышается, поскольку операционная система реже производит переключение процессов. Привязка позволяет также изолировать работу с базой данных, выделяя для этой цели определенные процессоры, в то время как остальные будут заняты другими задачами.
2.2.1.3 Планирование потоков
Сервер осведомлен о степени значимости различных потоков и в соответствии с этим назначает для них приоритеты. Например, потоки ввода-вывода получают приоритеты следующим образом:
Рис.2. Многопотоковая модель. Виртуальные процессоры (ВП) не простаивают, если имеются готовые к выполнению пользовательские или системные потоки.
INFORMIX-OnLine DS не полагается на механизмы потоков, имеющиеся в некоторых операционных системах. Он формирует потоки, специфичные для задач обработки баз данных, оптимальные в отношении выделяемой под них памяти, методов планирования и числа инструкций, затрачиваемых на переключение между потоками.
2.2.1.2 Виртуальные процессоры
Виртуальным процессором называется процесс сервера баз данных. Виртуальный процессор можно сравнить с операционной системой. Поток по отношению к нему выступает как процесс, подобно тому, как сам виртуальный процессор является процессом с точки зрения операционной системы.
Виртуальные процессоры (ВП) являются специализированными - они подразделяются на классы в соответствии с типом потоков, для выполнения которых они предназначены. Примеры классов ВП:
CPU - Потоки обслуживания клиентов, реализуют оптимизацию и логику выполнения запросов. К этому классу относятся и некоторые системные потоки.
AIO - Операции асинхронного обмена с диском.
ADM - Административные функции, например, системный таймер.
TLI - Контроль сетевого взаимодействия посредством интерфейса TLI (Transport Layer Interface).
В отличие от операционной системы, которая должна обеспечивать выполнение произвольных процессов, классы виртуальных процессоров спроектированы для наиболее оптимального выполнения заданий определенного вида.
Начальное число виртуальных процессоров каждого класса, создаваемых при запуске INFORMIX-OnLine DS, задается в конфигурационном файле. Однако, потребности в каждом виде обработки не всегда предсказуемы. Инструменты администрирования позволяют динамически, не останавливая сервер, запустить дополнительные виртуальные процессоры. Например, если растет очередь потоков к виртуальным CPU-процессорам, то можно увеличить их число. Точно так же, возможно добавление виртуальных процессоров обмена с дисками, сетевых процессоров взаимодействия с клиентами, создание процессора обмена с оптическим диском, если он отсутствовал в начальной конфигурации. Динамически сократить можно только число виртуальных процессоров класса CPU.
На некоторых мультипроцессорных платформах, где OnLine DS поддерживает родство процессоров (processor affinity), допускается привязка виртуальных CPU-процессоров к определенным центральным процессорам компьютера. В результате производительность виртуального CPU-процессора повышается, поскольку операционная система реже производит переключение процессов. Привязка позволяет также изолировать работу с базой данных, выделяя для этой цели определенные процессоры, в то время как остальные будут заняты другими задачами.
2.2.1.3 Планирование потоков
Сервер осведомлен о степени значимости различных потоков и в соответствии с этим назначает для них приоритеты. Например, потоки ввода-вывода получают приоритеты следующим образом:
- ввод-вывод логической журнализации - наивысший приоритет;
- ввод-вывод физической журнализации - второй по значимости приоритет;
- прочие операции ввода-вывода- низший приоритет.
Таким образом, гарантируется, что операции записи в логический журнал, от которых зависит восстановление базы данных в случае сбоя, не окажутся в очереди позади операции вывода во временный рабочий файл.
Сами виртуальные процессоры выполняются как высокоприоритетные процессы операционной системы, которые не прерываются, пока не пусты очереди готовых к выполнению потоков.
Выполнение потока не откладывается по истечении заданного кванта времени, как это происходит с процессами в операционной системе. Поток откладывается в двух случаях:
- когда он временно не может выполняться, например, если необходимо дождаться завершения обмена с диском, ввода данных от клиента, снятия блокировки.
- когда в коде потока встречаются обращения к функции yield. Обращения к ней вставляются при компиляции запросов, требующих длительной обработки, чтобы их выполнение не тормозило прохождение других потоков. Для этого выбираются точки, наиболее безболезненные для выполнения потока.
2.2.1.4 Разделение потоков между виртуальными процессорами.
Для каждого класса поддерживаются три очереди потоков, которые разделяются всеми виртуальными процессорами данного класса:
- Очередь готовых к выполнению потоков.
- Очередь спящих потоков. В нее помещается, например, CPU-поток, которому требуется доступ к диску. Предварительно CPU-поток порождает запрос на обмен с диском, для обслуживания которого формируется AIO-поток. Завершив обмен с диском, AIO-поток оповещает об этом виртуальный процессор CPU, который "будит" спящий CPU-поток и перемещает его в очередь готовых потоков.
- Очередь ждущих потоков. Эта очередь служит для координации доступа потоков к разделяемым ресурсам. В нее помещаются потоки, ожидающие какого-либо события, например, освобождения заблокированного ресурса. Когда поток, заблокировавший этот ресурс, готов освободить его, просматривается очередь ждущих потоков. Если в ней есть поток, ожидающий именно этот ресурс, то он перемещается в очередь готовых.
Если выполняемый поток завершается, засыпает или откладывается, то освободившийся виртуальный процессор выбирает из очереди готовых очередной поток с наивысшим приоритетом. Как правило, OnLine DS стремится выполнять поток на одном и том же виртуальном процессоре, поскольку передача его другому процессору требует пересылки некоторого объема данных. Тем не менее, если поток готов к выполнению, он может быть продолжен другим процессором, с целью исключения простоев и обеспечения общего баланса загрузки.
2.2.1.5 Экономия памяти и других ресурсов
Рациональное использование ресурсов операционной системы достигается за счет того, что потоки разделяют ресурсы (память, коммуникационные порты, файлы) виртуального процессора, на котором они выполняются. Виртуальный процессор сам координирует доступ потоков к своим ресурсам. Процессы же, в отличие от потоков, имеют индивидуальные наборы ресурсов, и, если ресурс требуется нескольким процессам, то доступ к нему регулируется операционной системой.
Переключение виртуального процессора с одного потока на другой, в целом, происходит быстрее, чем переключение операционной системы с одного процесса на другой. Операционная система должна прервать один процесс, выполняемый центральным процессором, сохранить его текущее состояние (контекст) и запустить другой процесс, предварительно поместив в ядро его контекст, что требует физической перезаписи фрагментов памяти. Поскольку потоки разделяют виртуальную память и дескрипторы файлов, то переключение виртуального процессора с потока на поток может сводиться к перезаписи небольшого управляющего блока потока, что соответствует выполнению примерно 20 машинных команд. При этом виртуальный процессор как процесс операционной системы продолжает выполняться без прерывания.
2.2.2 Организация разделяемой памяти
Разделяемая память - это механизм операционной системы, на котором основано разделение данных между виртуальными процессорами и потоками сервера. Разделение данных позволяет:
- Снизить общее потребление памяти, поскольку участвующим в разделении процессам, т. е. виртуальным процессорам, нет нужды поддерживать свои копии информации, находящейся в разделяемой памяти.
- Сократить число обменов с дисками, потому что буферы ввода-вывода сбрасываются на диск не для каждого процесса в отдельности, а образуют один общий для всего сервера баз данных пул. Виртуальный процессор зачастую избегает выполнения или обращения за результатами операций ввода с диска, поскольку нужная таблица уже прочитана другим процессором.
- Организовать быстрое взаимодействие между процессами. Через разделяемую память, в частности, обмениваются данными потоки, участвующие в параллельной обработке сложного запроса. Разделяемая память используется также для организации взаимодействия между локальным клиентом и сервером.
Управление разделяемой памятью реализовано таким образом, что ее фрагментация минимизируется, поэтому производительность сервера при ее использовании не деградирует с течением времени. Изначально выделенные сегменты разделяемой памяти наращиваются по мере надобности автоматически или вручную. При освобождении памяти, занятой сервером, она возвращается операционной системе.
В разделяемой памяти находится информация обо всех выполняемых потоках, поэтому потоки относительно быстро переключаются между виртуальными процессорами. В частности, в разделяемой памяти выделяется область стеков потоков. Стек хранит данные для функций, выполняемых потоком, и другую информацию о состоянии пользовательского сеанса. Размер стека для каждого сеанса устанавливается при помощи переменной окружения.
Важный оптимизирующий механизм сервера - кэши хранимых процедур и словарей данных. Словари данных (system catalog), доступные только на чтение, а также хранимые процедуры, разделяются между всеми пользователями сервера, что позволяет оптимизировать совокупное использование памяти. При загрузке в разделяемую память словарь данных записывается в структуры, обеспечивающие быстрый доступ к информации, а хранимые процедуры преобразуются в выполняемый формат. Все это может существенно ускорить выполнение приложений, обращающихся ко многим таблицам с большим числом столбцов и/или ко многим хранимым процедурам.
2.2.3 Организация операций обмена с дисками
Операции ввода-вывода, как правило, образуют наиболее медленную компоненту обработки баз данных. Поэтому от их реализации существенно зависит общая продуктивность сервера. Для оптимизации ввода-вывода и повышения надежности в сервере INFORMIX-OnLine DS применяются следующие механизмы:
- собственное управление дисковой памятью;
- асинхронный ввод-вывод;
- опережающее чтение.
2.2.3.1 Управление дисковой памятью
INFORMIX-OnLine DS поддерживает как собственный механизм управления дисковой памятью, так и управление средствами файловой системы ОС UNIX. Преимущества собственного механизма управления дисковой памятью:
- Снятие ограничений операционной системы на число одновременно читаемых таблиц.
- Оптимизация размещения таблиц - для таблиц выделяются большие области последовательных физических блоков, в результате ускоряется доступ к ним.
- Снижение накладных расходов при чтении - данные с дисков считываются непосредственно в разделяемую память, минуя буферы ОС.
- Повышение надежности. При использовании файловой системы INFORMIX-OnLine DS не может гарантировать, что в случае сбоя данные журнала транзакций не пропадут из-за того, что они остались в буферах ОС и не успели записаться на диск. Поэтому процедура быстрого восстановления, вызываемая при перезапуске системы, не обеспечит в этом случае целостности данных.
Файловую систему используют в ситуациях, когда нет возможности выделить под базы данных специальные разделы на дисках, или если перечисленные соображения не критичны.
2.2.3.2 Асинхронный ввод-вывод
Для ускорения операций ввода-вывода сервер использует собственный пакет асинхронного ввода-вывода (AIO) или пакет асинхронного ввода-вывода ядра ОС (KAIO), если он доступен. Пользовательские запросы на ввод-вывод обрабатываются асинхронно, поэтому виртуальным процессорам CPU не приходится ждать завершения операции обмена, чтобы продолжить обработку.
2.2.3.3 Опережающее чтение
Сервер OnLine DS может быть сконфигурирован таким образом, чтобы при чтении последовательной таблицы или индексного файла обеспечивалось опережающее чтение нескольких страниц в то время, пока обрабатываются уже прочитанные в разделяемую память данные. Таким образом, сокращается время ожидания обмена с диском, и пользователь быстрее получает результаты запроса.
2.2.4 Поддержка фрагментации таблиц и индексов
INFORMIX-OnLine DS поддерживает горизонтальную локальную фрагментацию таблиц. Это такой способ хранения таблицы, когда совокупность ее строк разбивается на несколько групп согласно некоторому правилу, и эти группы хранятся на разных дисковых разделах. Фрагментация таблиц способствует достижению следующих целей:
- Сокращается время обработки одного запроса. Встроенный в INFORMIX-OnLine DS механизм PDQ при обработке запросов использует информацию о фрагментации таблиц и создает для сканирования таблицы несколько параллельных потоков. Если стратегия фрагментации выбрана удачно, то ускорение при выборке из таблицы практически линейно зависит от числа фрагментов (рис. 3).
 Рис.3. Операции чтения-записи фрагментированной таблицы выполняются параллельно, в результате время обработки сокращается пропорционально числу фрагментов.
Рис.3. Операции чтения-записи фрагментированной таблицы выполняются параллельно, в результате время обработки сокращается пропорционально числу фрагментов.
- Снижается уровень конкуренции при одновременном обращении нескольких запросов к одной таблице. INFORMIX-OnLine DS анализирует правило фрагментации таблицы и во многих случаях способен определить, что данный запрос относится только к одному ее фрагменту. Если фрагменты хранятся на разных дисковых устройствах, то разным запросам будут соответствовать обращения к разным дискам.
- Повышается готовность (доступность) приложений. Даже если некоторые фрагменты таблицы недоступны из-за того, что соответствующие диски вышли из строя, запросы к ней, тем не менее, во многих случаях могут выполняться.
- Улучшаются характеристики административных операций, таких как архивирование-восстановление, загрузка-выгрузка данных, поскольку они применимы к отдельным фрагментам таблиц. Если таблица разбита на малые фрагменты, то ее восстановление при выходе из строя одного фрагмента выполняется значительно оперативнее, чем полное восстановление нефрагментированной таблицы. Полные операции архивирования, восстановления, загрузки, выгрузки данных также ускоряются, поскольку операции ввода-вывода для фрагментов таблицы выполняются параллельно.
Различаются два типа правил фрагментации таблиц:
- Равномерное распределение (round robin) - это встроенный в INFORMIX-OnLine DS механизм фрагментации, который обеспечивает примерно равное число записей в каждом фрагменте.
- Распределение по выражению (by expression) - для каждого фрагмента задается некоторое выражение, зависящее от значений полей записи; истинность выражения определяет, попадет ли запись в данный фрагмент.
Правило разбиения таблицы задается в SQL-инструкциях
CREATE TABLE (создать таблицу), ALTER TABLE (изменить таблицу). Пример:
CREATE TABLE account ...
FRAGMENT BY EXPRESSION
id_num > 0 AND id_num <= 20 IN dbsp1
id_num >20 AND id_num <= 40 IN dbsp2
REMAINDER IN dbsp3
Здесь dbsp1, dbsp2, dbsp3 - имена областей дискового пространства, выделенного под БД.
INFORMIX-OnLine DS поддерживает также фрагментацию индексов. Различаются два вида фрагментации индексов - зависимая (соответствующая фрагментации таблицы) и независимая. Фрагментированной таблице может соответствовать нефрагментированный индекс. Создание индекса с правилом фрагментации, не совпадающим с правилом фрагментации таблицы, полезно в тех случаях, когда в разных приложениях выборки из таблицы осуществляются на основе разных подмножеств ее атрибутов.
Стратегия фрагментации таблиц и индексов выбирается в зависимости от цели, которая преследуется, от структуры таблицы и характера запросов к ней. Различные стратегии подробно описаны в документации. Например, если основной целью является уменьшение конкуренции при одновременном доступе к таблице, то оптимальной будет фрагментация таблицы по диапазонам значения ключа (или другого столбца, на основе которого производится основной доступ к таблице) и зависимая фрагментация индекса.
INFORMIX-OnLine DS предоставляет средства наблюдения, позволяющие оценить эффективность фрагментации таблиц и индексов по следующим параметрам:
- Распределение данных по фрагментам;
- Баланс запросов на ввод-вывод по фрагментам;
- Статус дисковых областей, содержащих фрагменты.
Если наблюдения показывают, что выбранная стратегия не удовлетворяет поставленной цели, то правила фрагментации могут быть изменены динамически, без остановки сервера.
Важно, что фрагментация таблиц и индексов прозрачна для приложений, работающих с базой данных. Изменение правила фрагментации не требует никаких изменений в прикладных системах - оно лишь повышает (или снижает) скорость и экономичность их выполнения.
2.2.5 Параллельная обработка запросов
Параллельная обработка запросов (Parallel Data Query, PDQ) - это технология, которая позволяет распределить обработку одного сложного запроса на несколько процессоров, мобилизовать для его выполнения максимально доступные системные ресурсы, во много раз сокращая время получения результата. Основные типы заданий, на которых проявляется эффект технологии PDQ:
- обработка сложных запросов, включающих сканирование больших таблиц, сортировку, соединения, группирование, массовые вставки;
- построение индексов;
- сохранение и восстановление данных;
- загрузка, выгрузка данных, реорганизация баз данных;
- массовые операции вставки, удаления, модификации данных.
Практически это означает, что отчет или ответ на сложный запрос, от которого зависит принятие ответственного решения, можно получить не завтра (после ночной обработки), а непосредственно во время обычной оперативной дневной работы. Снимаются проблемы, связанные с обработкой и обслуживанием (архивированием, копированием) очень больших таблиц - благодаря фрагментации, параллельной обработке и возможностям выполнения административных действий в оперативном режиме. В результате расширяется класс потенциальных приложений, и, соответственно, круг пользователей, более гибким становится режим работы ИС, причем все это достигается не на узкоспециализированных, а на обычных широко распространенных аппаратных платформах. Таким образом, можно говорить о новом качестве, которое привносит с собой технология PDQ.
Максимальные преимущества эта технология дает на многопроцессорных платформах в условиях применения фрагментации таблиц, где время выполнения запроса сокращается в десятки раз; однако выигрыш в производительности достигается и на однопроцессорных машинах и нефрагментированных таблицах за счет того, что доступ к дискам осуществляется параллельно с другими видами обработки, и за счет максимально полного использования памяти.
2.2.5.1 На чем основана технология PDQ
Реализация запроса состоит из отдельных действий - сканирования, сортировки, группирования и др. Эти действия называются итераторами. Итераторы образуют дерево реализации запроса в том смысле, что результаты выполнения одних итераторов являются исходными данными для других. При обычной обработке итераторы выполняются последовательно. В основе технологии PDQ лежат следующие виды оптимизации и регулирования:
- Параллельный ввод и вывод (на основе горизонтальной фрагментации таблиц).
- Распараллеливание отдельных итераторов (на основе методов разбиения данных).
- Распараллеливание плана выполнения запроса (путем разбиения дерева реализации запроса на независимые поддеревья; за счет применения техники потоков данных).
- Снижение вычислительной сложности алгоритмов (применение основанных на хешировании алгоритмов сортировки, соединения, вычисления агрегатных функций (sum, min, max, avg, ...)).
- Управление ресурсами, регулирование степени распараллеливания (под PDQ выделяется определенная доля системных ресурсов).
2.2.5.2 Итераторы
Итератор - это программный объект, который осуществляет итеративную (циклическую) обработку некоторого множества данных. Итераторы различаются типом производимой обработки, но имеют единообразный внешний интерфейс (рис. 4). Каждый итератор открывает один (или более) входных потоков данных (data flow), последовательно считывает их и, после обработки, помещает результаты в выходной поток. Итератору безразличен источник входного потока и назначение выходного потока - это может быть диск, другой итератор, сетевое соединение. Мы будем говорить о поставщиках и потребителях потоков данных. Ниже перечислены типы итераторов, применяемые в INFORMIX-OnLine DS:
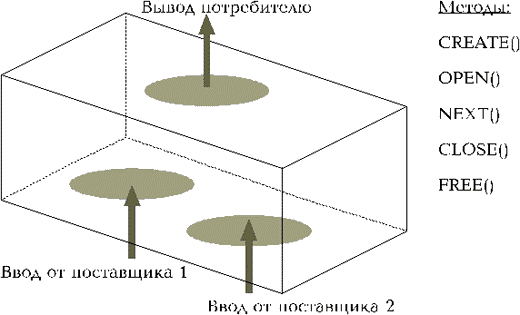 Рис. 4. Работа итератора не зависит от источников входных данных. Вывод поступает объекту, который вызвал итератор.
SCAN - Сканирует фрагментированные и нефрагментированные таблицы и индексы.
NESTED LOOP JOIN - Реализует стандартную логику соединений методом вложенных циклов (читает строку из одной таблицы, находит все совпадения во второй таблице, читает следующую строку из первой таблицы и т. д.).
MERGE JOIN - Выполняет фазу слияния для соединения методом сортировки и слияния.
HASH JOIN - Реализует новый метод соединений с хешированием. Для одной из двух соединяемых таблиц строится хеш-таблица, вторая таблица зондируется. Оптимизатор решает, какая из таблиц будет хешироваться.
GROUP - Группирует данные (GROUP BY) и вычисляет агрегатные функции.
SORT - Сортирует данные.
MERGE - Выполняет объединения UNION и UNION ALL (для UNION используется комбинация итераторов MERGE и SORT).
REMOTE - Реализует удаленные сканирования для операторов SELECT.
Итератор как программный объект состоит из статических и динамических структур данных. Статическая структура содержит ссылки на функции (или методы), применимые к итератору. Динамическая структура содержит информацию о текущем состоянии итератора (открыт, закрыт, выполняет очередную итерацию), одну или две ссылки на поставщиков.
Методы итератора
CREATE() - Создает итератор. Выделяет память для итератора, инициализирует его структуры, а также остальные методы (open(), next(), close(), free()), т.е. устанавливает ссылки на функции, соответствующие данному типу итератора. Затем вызывает метод create() для своих итераторов-поставщиков, которые создадут своих поставщиков, если таковые имеются, и т. д. Таким образом, вызов метода create() для корневого итератора приводит к созданию всего дерева итераторов.
OPEN() - Запускает итератор. Выполняются специфические для данного типа итератора инициализирующие действия, возможно, запрос дополнительной памяти. Например, при запуске итератора сканирования определяется, какие фрагменты необходимо сканировать, устанавливается указатель на первый из них, создается временная таблица (если она нужна), посылается сообщение
MGM (MGM - компонента сервера, которая регулирует выделение ресурсов под запросы, обрабатываемые средствами PDQ; см. об этом ниже, п. "Баланс между OLTP и DSS-приложениями") о запуске потока сканирования. Далее применяется метод open() по отношению к поставщикам итератора, которые применят его к своим поставщикам и т.д. Таким образом, для запуска всего дерева итераторов достаточно применить метод open() к корневому итератору.
NEXT() - Выполняет одну итерацию. Выполнение начинается с того, что итератор применяет метод next() к своим поставщикам, заставляя их также применить next() к своим поставщикам и т. д., пока не сработают итерации поставщиков нижнего уровня. Затем данные поднимаются снизу вверх - каждый итератор, получив данные от своего поставщика, применяет к ним свой специфический вид обработки и передает результат своему потребителю. Метод next() применяется циклически, пока не поступит признак конца потока данных.
CLOSE() - Закрывает итератор. Высвобождает память, выделенную при запуске. Фактически, эта память могла уже быть высвобождена методом next(), когда он получил признак конца данных, поскольку общий принцип состоит в том, чтобы освобождать память сразу же, как только она становится не нужна. Однако, это не всегда возможно. Поэтому на метод close() возлагается ответственность за то, чтобы память в любом случае была освобождена.
Метод close() рекурсивно применяется к поставщикам, тем самым, закрывается все дерево итераторов.
FREE() - Освобождает итератор. Высвобождает память, выделенную при создании. Применяет free() к поставщикам, таким образом, освобождается все дерево итераторов.
Благодаря единообразию интерфейса, итераторы разных типов могут соединяться друг с другом произвольным образом (рис. 5). Итератор не заботится о том, какой тип имеют его поставщики, поскольку он взаимодействует с ними только посредством методов. Из описания методов следует, что запуск дерева, составленного из итераторов, реализует их параллельное выполнение. Для каждого итератора создается поток выполнения, который продвигается по мере того, как получает данные от своих поставщиков. Таким образом в сервере реализуется вертикальный параллелизм - одновременное, конвейерное выполнение различных итераторов.
Рис. 4. Работа итератора не зависит от источников входных данных. Вывод поступает объекту, который вызвал итератор.
SCAN - Сканирует фрагментированные и нефрагментированные таблицы и индексы.
NESTED LOOP JOIN - Реализует стандартную логику соединений методом вложенных циклов (читает строку из одной таблицы, находит все совпадения во второй таблице, читает следующую строку из первой таблицы и т. д.).
MERGE JOIN - Выполняет фазу слияния для соединения методом сортировки и слияния.
HASH JOIN - Реализует новый метод соединений с хешированием. Для одной из двух соединяемых таблиц строится хеш-таблица, вторая таблица зондируется. Оптимизатор решает, какая из таблиц будет хешироваться.
GROUP - Группирует данные (GROUP BY) и вычисляет агрегатные функции.
SORT - Сортирует данные.
MERGE - Выполняет объединения UNION и UNION ALL (для UNION используется комбинация итераторов MERGE и SORT).
REMOTE - Реализует удаленные сканирования для операторов SELECT.
Итератор как программный объект состоит из статических и динамических структур данных. Статическая структура содержит ссылки на функции (или методы), применимые к итератору. Динамическая структура содержит информацию о текущем состоянии итератора (открыт, закрыт, выполняет очередную итерацию), одну или две ссылки на поставщиков.
Методы итератора
CREATE() - Создает итератор. Выделяет память для итератора, инициализирует его структуры, а также остальные методы (open(), next(), close(), free()), т.е. устанавливает ссылки на функции, соответствующие данному типу итератора. Затем вызывает метод create() для своих итераторов-поставщиков, которые создадут своих поставщиков, если таковые имеются, и т. д. Таким образом, вызов метода create() для корневого итератора приводит к созданию всего дерева итераторов.
OPEN() - Запускает итератор. Выполняются специфические для данного типа итератора инициализирующие действия, возможно, запрос дополнительной памяти. Например, при запуске итератора сканирования определяется, какие фрагменты необходимо сканировать, устанавливается указатель на первый из них, создается временная таблица (если она нужна), посылается сообщение
MGM (MGM - компонента сервера, которая регулирует выделение ресурсов под запросы, обрабатываемые средствами PDQ; см. об этом ниже, п. "Баланс между OLTP и DSS-приложениями") о запуске потока сканирования. Далее применяется метод open() по отношению к поставщикам итератора, которые применят его к своим поставщикам и т.д. Таким образом, для запуска всего дерева итераторов достаточно применить метод open() к корневому итератору.
NEXT() - Выполняет одну итерацию. Выполнение начинается с того, что итератор применяет метод next() к своим поставщикам, заставляя их также применить next() к своим поставщикам и т. д., пока не сработают итерации поставщиков нижнего уровня. Затем данные поднимаются снизу вверх - каждый итератор, получив данные от своего поставщика, применяет к ним свой специфический вид обработки и передает результат своему потребителю. Метод next() применяется циклически, пока не поступит признак конца потока данных.
CLOSE() - Закрывает итератор. Высвобождает память, выделенную при запуске. Фактически, эта память могла уже быть высвобождена методом next(), когда он получил признак конца данных, поскольку общий принцип состоит в том, чтобы освобождать память сразу же, как только она становится не нужна. Однако, это не всегда возможно. Поэтому на метод close() возлагается ответственность за то, чтобы память в любом случае была освобождена.
Метод close() рекурсивно применяется к поставщикам, тем самым, закрывается все дерево итераторов.
FREE() - Освобождает итератор. Высвобождает память, выделенную при создании. Применяет free() к поставщикам, таким образом, освобождается все дерево итераторов.
Благодаря единообразию интерфейса, итераторы разных типов могут соединяться друг с другом произвольным образом (рис. 5). Итератор не заботится о том, какой тип имеют его поставщики, поскольку он взаимодействует с ними только посредством методов. Из описания методов следует, что запуск дерева, составленного из итераторов, реализует их параллельное выполнение. Для каждого итератора создается поток выполнения, который продвигается по мере того, как получает данные от своих поставщиков. Таким образом в сервере реализуется вертикальный параллелизм - одновременное, конвейерное выполнение различных итераторов.
 Рис. 5. Итераторы выполняются параллельно, каждый может продвигаться по мере того, как поступают данные от его поставщиков.
Другой вид параллелизма - горизонтальный - заключается в том, что вместо одного итератора (например, сканирования) создается несколько однотипных параллельно выполняемых итераторов. Горизонтальный параллелизм реализуется при помощи итераторов специального вида - итераторов обмена (EXCHANGE). После того, как дерево реализации запроса построено, оптимизатор определяет, какие его компоненты имеет смысл распараллелить. Над такой компонентой вставляется итератор EXCHANGE. Итератор EXCHANGE создает и запускает несколько экземпляров своего поставщика, обеспечивает координацию поступающих от них потоков данных и их передачу своему потребителю. Передача данных осуществляется в этом случае не через входы потребителя, а через очереди пакетов в разделяемой памяти.
Степень и наиболее оптимальные способы применения вертикального и горизонтального параллелизма для каждого конкретного запроса определяется оптимизатором. Оптимизатор принимает решения, исходя из значений параметров конфигурации, устанавливаемых администратором, пользователем и клиентским приложением, а также с учетом некоторых внутренних соображений, таких как число наличных процессоров, фрагментация участвующих в запросе таблиц, сложность запроса и т. д.
Результаты тестов показывают, что механизмы PDQ и оптимизации INFORMIX-OnLine DS обеспечивают с увеличением числа процессоров практически пропорциональный рост производительности.
2.2.5.3 Примеры применения параллелизма
Параллельная сортировка
Сортировка - это фундаментальная операция обработки баз данных, применяемая при выполнении таких действий, как построение индексов, соединение методом сортировки и слияния, группирование; поэтому ускорение сортировки улучшает качество многих приложений.
При параллельной сортировке совокупность данных разбивается на секции, которые передаются для сортировки нескольким процессорам. Затем выполняется слияние отсортированных секций.
На практике скорость сортировки ограничивается временем сканирования данных из таблиц. Это ограничение в значительной мере снимается применением PDQ-алгоритмов параллельного сканирования.
Параллельное сканирование
Операции построения индексов, соединений, подготовки отчетов, необходимые в большинстве приложений, требуют сканирования больших объемов данных, если в них участвуют большие таблицы. Технология PDQ позволяет существенно снизить время сканирования. Если таблица фрагментирована, то секции сканируются параллельно, при этом выигрыш во времени примерно пропорционален числу дисков. При сканировании последовательных таблиц или индексов применяется конфигурация сервера OnLine DS с опережающим чтением - время отклика сокращается за счет того, что чтение очередных страниц идет параллельно с обработкой уже прочитанных.
Параллельное построение индексов
Процедура построения индекса начинается с оценки объема данных и определения числа потоков, необходимых для их сканирования. Затем выполняется параллельное сканирование данных с применением, там, где это возможно, опережающего чтения. Считанные данные помещаются в участки разделяемой памяти, и запускается параллельная сортировка участков, для каждого из которых строится Вподдерево; затем из них формируется общий индекс. Потоки сортировки начинают выполняться, не дожидаясь завершения всех потоков сканирования, точно так же, поток построения индекса не ожидает завершения всех потоков сортировки - все, что можно, выполняется параллельно. В результате достигается ускорение, вплоть до десятикратного, по сравнению с последовательными методами построения индексов - в зависимости от объемов данных, числа используемых дисков и доступной памяти.
2.2.5.4 Баланс между OLTP и DSS-приложениями
В современных информационных системах, как правило, требуется одновременное выполнение разных по характеру запросов к базе данных. Выделяются приложения обработки данных типа OLTP, DSS и пакетной обработки.
Пример OLTP-запроса: Есть ли свободный номер в какой-либо берлинской гостинице на 8-е декабря?
Пример DSS-запроса: Каковы будут затраты на реализацию стратегии X охраны здоровья сотрудников по сравнению со стратегией Y с учетом демографического профиля компании? Зависит ли эффективность стратегии от региона?
Примерами заданий пакетной обработки могут служить массовая загрузка данных, выдача больших сложных отчетов, выполнение некоторых административных действий, например, по реорганизации базы данных.
Ответы на запросы первого типа должны выдаваться практически мгновенно, запросы второго и третьего типов могут обслуживаться достаточно долго, но при отсутствии или малой интенсивности OLTP-приложений желательно получать ответы на DSS-запросы максимально быстро.
Технология PDQ используется в основном для быстрого выполнения DSS-запросов и пакетных приложений. Если ее применение ничем не ограничено, то сильно распараллеленное выполнение нескольких сложных запросов приводит к недопустимому замедлению OLTP-приложений, выполняющихся на том же сервере. Управление степенью распараллеливания запросов и долей системных ресурсов, выделяемых для PDQ-обработки, в среде INFORMIX-OnLine DS осуществляется при помощи нескольких параметров конфигурирования и переменных окружения, значения которых динамически настраиваемы. Значения этих параметров и переменных устанавливаются системными администраторами и, в определенной степени, прикладными программистами и пользователями.
Программист или пользователь задает тип каждого запроса (обычный или PDQ) и желаемую степень распараллеливания для PDQ-запросов. Администратор, со своей стороны, динамически ограничивает максимальную допустимую степень распараллеливания PDQ-запросов, а также определяет долю системных ресурсов, выделяемых под обработку PDQ-запросов. Параллельная сортировка применяется для любых запросов, в том числе, обычных.
Таким образом, режим работы сервера INFORMIX-OnLine DS может динамически изменяться. В часы наиболее активной работы приложений OLTP запросы DSS выполняются без распараллеливания (когда для каждого запроса создается всегда только один поток класса CPU) или с невысокой степенью распараллеливания. В остальное время, или на серверах, где приложения OLTP отсутствуют, устанавливается максимальная степень использования PDQ.
Собственно распределением ресурсов и приоритетов в соответствии с установленными значениями занимается специальная компонента сервера OnLine DS - Менеджер выделения памяти (Memory Grant Manager - MGM). Менеджер выделения памяти регулирует объем системных ресурсов, потребляемых PDQ-заданиями, а также:
Рис. 5. Итераторы выполняются параллельно, каждый может продвигаться по мере того, как поступают данные от его поставщиков.
Другой вид параллелизма - горизонтальный - заключается в том, что вместо одного итератора (например, сканирования) создается несколько однотипных параллельно выполняемых итераторов. Горизонтальный параллелизм реализуется при помощи итераторов специального вида - итераторов обмена (EXCHANGE). После того, как дерево реализации запроса построено, оптимизатор определяет, какие его компоненты имеет смысл распараллелить. Над такой компонентой вставляется итератор EXCHANGE. Итератор EXCHANGE создает и запускает несколько экземпляров своего поставщика, обеспечивает координацию поступающих от них потоков данных и их передачу своему потребителю. Передача данных осуществляется в этом случае не через входы потребителя, а через очереди пакетов в разделяемой памяти.
Степень и наиболее оптимальные способы применения вертикального и горизонтального параллелизма для каждого конкретного запроса определяется оптимизатором. Оптимизатор принимает решения, исходя из значений параметров конфигурации, устанавливаемых администратором, пользователем и клиентским приложением, а также с учетом некоторых внутренних соображений, таких как число наличных процессоров, фрагментация участвующих в запросе таблиц, сложность запроса и т. д.
Результаты тестов показывают, что механизмы PDQ и оптимизации INFORMIX-OnLine DS обеспечивают с увеличением числа процессоров практически пропорциональный рост производительности.
2.2.5.3 Примеры применения параллелизма
Параллельная сортировка
Сортировка - это фундаментальная операция обработки баз данных, применяемая при выполнении таких действий, как построение индексов, соединение методом сортировки и слияния, группирование; поэтому ускорение сортировки улучшает качество многих приложений.
При параллельной сортировке совокупность данных разбивается на секции, которые передаются для сортировки нескольким процессорам. Затем выполняется слияние отсортированных секций.
На практике скорость сортировки ограничивается временем сканирования данных из таблиц. Это ограничение в значительной мере снимается применением PDQ-алгоритмов параллельного сканирования.
Параллельное сканирование
Операции построения индексов, соединений, подготовки отчетов, необходимые в большинстве приложений, требуют сканирования больших объемов данных, если в них участвуют большие таблицы. Технология PDQ позволяет существенно снизить время сканирования. Если таблица фрагментирована, то секции сканируются параллельно, при этом выигрыш во времени примерно пропорционален числу дисков. При сканировании последовательных таблиц или индексов применяется конфигурация сервера OnLine DS с опережающим чтением - время отклика сокращается за счет того, что чтение очередных страниц идет параллельно с обработкой уже прочитанных.
Параллельное построение индексов
Процедура построения индекса начинается с оценки объема данных и определения числа потоков, необходимых для их сканирования. Затем выполняется параллельное сканирование данных с применением, там, где это возможно, опережающего чтения. Считанные данные помещаются в участки разделяемой памяти, и запускается параллельная сортировка участков, для каждого из которых строится Вподдерево; затем из них формируется общий индекс. Потоки сортировки начинают выполняться, не дожидаясь завершения всех потоков сканирования, точно так же, поток построения индекса не ожидает завершения всех потоков сортировки - все, что можно, выполняется параллельно. В результате достигается ускорение, вплоть до десятикратного, по сравнению с последовательными методами построения индексов - в зависимости от объемов данных, числа используемых дисков и доступной памяти.
2.2.5.4 Баланс между OLTP и DSS-приложениями
В современных информационных системах, как правило, требуется одновременное выполнение разных по характеру запросов к базе данных. Выделяются приложения обработки данных типа OLTP, DSS и пакетной обработки.
Пример OLTP-запроса: Есть ли свободный номер в какой-либо берлинской гостинице на 8-е декабря?
Пример DSS-запроса: Каковы будут затраты на реализацию стратегии X охраны здоровья сотрудников по сравнению со стратегией Y с учетом демографического профиля компании? Зависит ли эффективность стратегии от региона?
Примерами заданий пакетной обработки могут служить массовая загрузка данных, выдача больших сложных отчетов, выполнение некоторых административных действий, например, по реорганизации базы данных.
Ответы на запросы первого типа должны выдаваться практически мгновенно, запросы второго и третьего типов могут обслуживаться достаточно долго, но при отсутствии или малой интенсивности OLTP-приложений желательно получать ответы на DSS-запросы максимально быстро.
Технология PDQ используется в основном для быстрого выполнения DSS-запросов и пакетных приложений. Если ее применение ничем не ограничено, то сильно распараллеленное выполнение нескольких сложных запросов приводит к недопустимому замедлению OLTP-приложений, выполняющихся на том же сервере. Управление степенью распараллеливания запросов и долей системных ресурсов, выделяемых для PDQ-обработки, в среде INFORMIX-OnLine DS осуществляется при помощи нескольких параметров конфигурирования и переменных окружения, значения которых динамически настраиваемы. Значения этих параметров и переменных устанавливаются системными администраторами и, в определенной степени, прикладными программистами и пользователями.
Программист или пользователь задает тип каждого запроса (обычный или PDQ) и желаемую степень распараллеливания для PDQ-запросов. Администратор, со своей стороны, динамически ограничивает максимальную допустимую степень распараллеливания PDQ-запросов, а также определяет долю системных ресурсов, выделяемых под обработку PDQ-запросов. Параллельная сортировка применяется для любых запросов, в том числе, обычных.
Таким образом, режим работы сервера INFORMIX-OnLine DS может динамически изменяться. В часы наиболее активной работы приложений OLTP запросы DSS выполняются без распараллеливания (когда для каждого запроса создается всегда только один поток класса CPU) или с невысокой степенью распараллеливания. В остальное время, или на серверах, где приложения OLTP отсутствуют, устанавливается максимальная степень использования PDQ.
Собственно распределением ресурсов и приоритетов в соответствии с установленными значениями занимается специальная компонента сервера OnLine DS - Менеджер выделения памяти (Memory Grant Manager - MGM). Менеджер выделения памяти регулирует объем системных ресурсов, потребляемых PDQ-заданиями, а также:
- устанавливает приоритет каждого запроса;
- следит за тем, чтобы одновременно выполнялось не более заданного числа PDQ-запросов;
- следит за тем, чтобы объем разделяемой памяти, занятой под обработку сложных запросов, не превышал заданного уровня;
- совместно с оптимизатором запросов обеспечивает максимальную при заданных параметрах степень параллелизма на всех уровнях.
2.2.6 Оптимизатор выполнения запросов по стоимости
Оптимизатор запросов определяет наиболее оптимальный с точки зрения затрат системных ресурсов план реализации каждого запроса к базе данных. Учитывается число обменов с диском, затраты разделяемой памяти, затраты на пересылку данных по сети и др. План может включать параллельное выполнение операций или быть строго последовательным, что зависит как от структуры запроса, так и от ресурсов, выделяемых MGM. Оптимизатор опирается на статистическую информацию о распределении данных по столбцам таблиц, периодическим сбором которой управляет администратор.
Например, если требуется выполнить соединение двух таблиц, находящихся в разных узлах сети, то оптимизатор спланирует эту операцию таким образом, что меньшая по объему таблица будет передана на сервер, содержащий большую таблицу, где и будет выполнено соединение (не обязательно выполнять его на том сервере, к которому произведено первое подключение). Дополнительная оптимизация достигается за счет фильтрации таблицы перед ее пересылкой, т. е. изъятия из нее не участвующих в данной операции соединения строк и/или столбцов.
Оптимизатор дает возможность разработчику предварительно получить план выполнения запроса, в том числе, распределенной транзакции. Получив такой план, разработчик может выяснить, что не располагает достаточной памятью, чтобы сохранить полученные в результате данные, или что выполнение запроса потребует слишком больших затрат системных ресурсов. В такой ситуации он либо отложит выполнение запроса на другое время, либо переформулирует запрос так, чтобы сузить объем возвращаемых данных, либо примет какое-то другое решение.
Прикладной программист или пользователь устанавливает один из двух возможных уровней оптимизации - высокий или низкий. Высокий уровень оптимизации предполагает перебор большого числа возможных вариантов и сам требует больших затрат системных ресурсов, в частности, памяти. Оптимизация низкого уровня обходится дешевле, поскольку перебирается небольшое число предположительно оптимальных вариантов, но остается вероятность "упустить" наилучший вариант. Например, план выполнения хранимой процедуры вычисляется заранее с высоким уровнем оптимизации и сохраняется, после чего устанавливается низкий уровень - тогда при обращении к процедуре используется построенный заранее наиболее оптимальный план.
2.2.7 Средства обеспечения надежности
Сервер INFORMIX-OnLine DS предоставляет следующие средства для восстановления после сбоев и обеспечения отказоустойчивости:
- Зеркалирование дисковых областей
- Полное тиражирование данных сервера
- Быстрое восстановление при включении системы
- Средства архивирования данных
2.2.7.1 . Зеркалирование дисковых областей
Зеркалирование в INFORMIX-OnLine DS - это дублирование связной дисковой области, выделенной под базу данных, на такую же по размеру область. Исходная область называется первичной, а ее копия - зеркальной. Цели, для которых применяется зеркалирование - высокая готовность и оптимизация операций чтения.
Высокая готовность достигается за счет того, что при выходе из строя диска, на котором находится первичная область, сервер автоматически продолжает работу с оставшимся диском без перехода сервера в режим off-line. Все операции чтения-записи происходят с зеркальной областью (при условии, что она находится на другом диске). Восстановление копии на первичном диске после его включения производится в оперативном режиме.
Затраты на зеркалирование складываются из затрат дискового пространства и затрат на дополнительные операции записи. В условиях, когда имеется несколько виртуальных процессоров обмена с диском, операции записи на оба диска производятся параллельно, и затраты второго рода сводятся к минимуму. К тому же они компенсируются оптимизацией операций чтения, о которой говорится ниже.
В идеальном случае зеркалирование должно быть обеспечено для всех областей базы данных. Крайне желательно поддерживать зеркалирование для критичных областей, составляющих корневое пространство базы данных и пространства, где хранятся логический и физический журналы. При выходе из строя любого из них, если нет зеркального дубля, сервер немедленно переводится в режим off-line. При отказе других незеркалируемых областей недоступными становятся только хранящиеся на них таблицы или фрагменты таблиц - до завершения процедуры их восстановления. Поэтому для наиболее критичных таблиц также желательно поддерживать зеркалирование.
Оптимизация операций чтения достигается за счет разбиения (split read). Страницы, относящиеся к начальной половине области, читаются с первичной области, а страницы из второй половины - с зеркальной. В результате ускоряется поиск страницы на диске, поскольку максимальный пробег дисковых головок сокращается вдвое.
2.2.7.2 Тиражирование
Тиражирование - это поддержание на другой вычислительной установке копии объектов базы данных. В INFORMIX-OnLine DS реализовано прозрачное тиражирование данных с основного сервера баз данных на вторичный (или поддерживающий) сервер, к которому разрешен доступ только на чтение и который может находиться в другом географическом пункте. В этой терминологии сервер, не участвующий в тиражировании, называется стандартным.
Главная цель тиражирования в INFORMIX-OnLine DS - это обеспечение высокой готовности (High Availability Data Replication - HDR). В случае отказа основного сервера вторичному серверу автоматически или вручную придается статус стандартного, с доступом на чтение и запись (рис. 6, рис. 7). Прозрачное перенаправление клиентов при отказе основного сервера не поддерживается, но оно может быть реализовано в рамках приложений.
 Рис. 6. Тиражирование. Основной сервер доступен на чтение и запись, вторичный - только на чтение.
Рис. 6. Тиражирование. Основной сервер доступен на чтение и запись, вторичный - только на чтение.
 Рис. 7. Когда основной сервер выходит из строя, вторичный переходит в режим стандартного сервера и становится доступен на чтение и запись.
После восстановления основного сервера, в зависимости от значения параметра конфигурации, выбирается один из двух возможных сценариев:
Рис. 7. Когда основной сервер выходит из строя, вторичный переходит в режим стандартного сервера и становится доступен на чтение и запись.
После восстановления основного сервера, в зависимости от значения параметра конфигурации, выбирается один из двух возможных сценариев: